> ## Documentation Index
> Fetch the complete documentation index at: https://inference-docs.cerebras.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Hyper-Personalized Web Pages
> Build hyper-personalized web pages using Cerebras AI with Pydantic structured outputs and Jinja2 templating—pages that adapt to each visitor's preferred colors, tone, and products in real-time.
export const CookbookLayout = () => {
return
;
};
export const AuthorBlock = ({name, title, date, githubUrl}) => {
return
{name}
{title && <>{title} }
{date && <>{date} }
{githubUrl &&
Open in Github
}
;
};
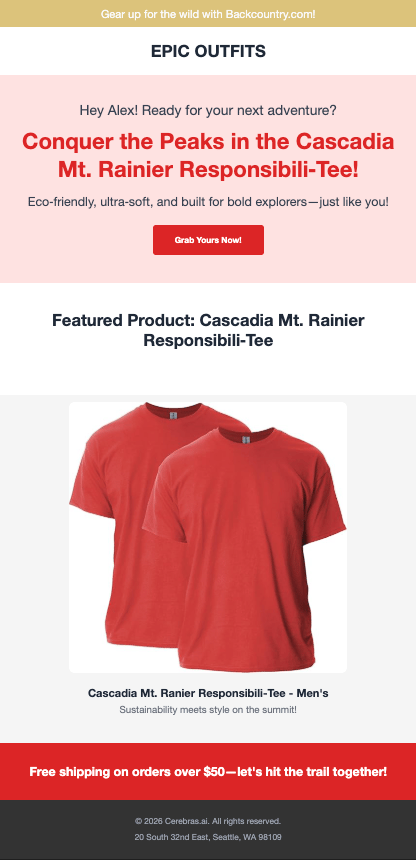 *Alex's page: Casual tone, English, red accent color, extroverted personality*
*Alex's page: Casual tone, English, red accent color, extroverted personality*
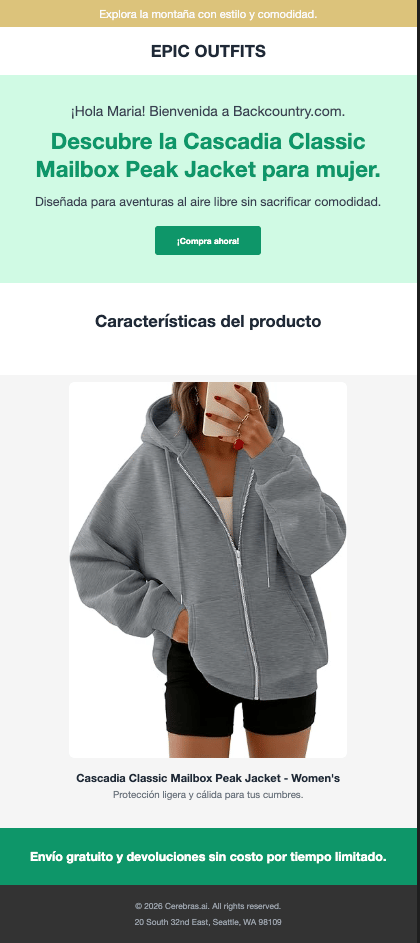 *Maria's page: Friendly tone, Spanish, green accent color, balanced personality*
*Maria's page: Friendly tone, Spanish, green accent color, balanced personality*
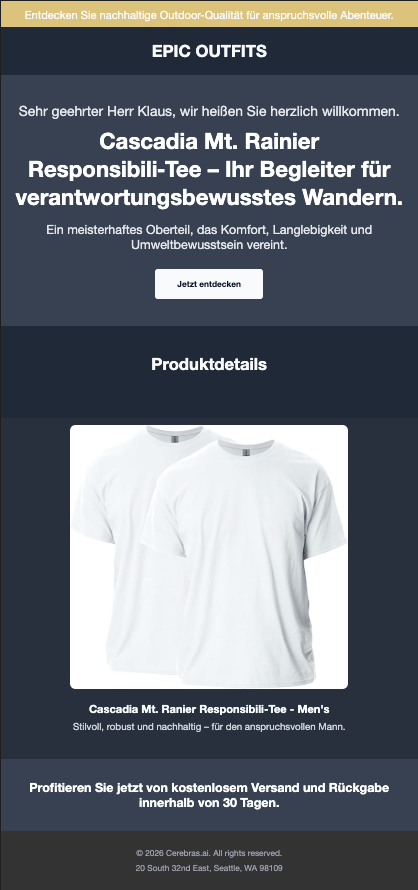 *Klaus's page: Formal tone, German, white accent color, introverted personality*
### Why This Matters
Research shows that hyper-personalization significantly increases user engagement. According to Zarouali et al. (2020), personalized content that adapts to individual preferences including tone, and messaging leads to **higher perceived relevance and stronger behavioral intentions** compared to generic content.
With Cerebras' ultra-fast inference, this level of personalization becomes practical for real-time web experiences. What used to require batch processing or slow generation can now happen at page-load speed, creating truly dynamic user experiences.
## Performance
| Metric | Value |
| -------------------------- | ---------------------------------------------------------- |
| Average generation time | \~0.4s per page |
| Tokens per page | \~800-900 |
| Languages supported | English, Spanish, German (extensible) |
| Personalization dimensions | 6 (language, tone, personality, color, gender, background) |
Cerebras enables real-time personalization at scale—generate thousands of unique pages per minute.
```python theme={null}
print("\n" + "="*60)
print("⚡ CEREBRAS PERFORMANCE SUMMARY")
print("="*60)
times, tokens = [], 0
for i, user in enumerate(users):
content, elapsed, usage = generate_page_content(user)
times.append(elapsed)
tokens += usage['total_tokens']
lang = LANGUAGE_MAP.get(user.preferred_language, "en")[:2]
print(f"User {i+1}: {lang} | {user.tone} | {user.personality} → {elapsed:.2f}s")
print(f"\n📊 Average: {sum(times)/len(times):.2f}s per page")
print(f"📊 Total: {sum(times):.2f}s for {len(users)} pages")
print(f"📊 Tokens: {tokens} total ({tokens//len(users)} avg)")
print(f"\n🚀 Real-time personalization at scale!")
```
## Summary
### What We Built
A **hyper-personalized web page system** where pages adapt to each visitor:
* **Preferred colors** - Visual styling matches user preferences
* **Tone & personality** - Content adapts from formal to casual
* **Products** - Featured items match user demographics
* **Language** - Full multilingual support
All powered by **Cerebras' ultra-fast inference** (\~0.4s per page), making real-time personalization practical at scale.
### Key Patterns
1. **Schema-constrained generation**: Use `response_format` with JSON schema for reliable outputs
2. **Pydantic validation**: Validate all LLM responses before use
3. **Template separation**: LLM generates text, templates handle layout/styling
4. **Concise prompts**: Shorter prompts reduce latency and cost
### Next Steps
* Add A/B testing for different content variations
* Implement click tracking and conversion analytics
* Add more personalization dimensions (purchase history, browsing behavior)
* Deploy as a real-time API for e-commerce personalization
### Resources
* [Cerebras Inference Docs](https://inference-docs.cerebras.ai)
* [Pydantic Docs](https://docs.pydantic.dev)
* [Jinja2 Docs](https://jinja.palletsprojects.com)
* [Zarouali, B., Dobber, T., De Pauw, G., & de Vreese, C. (2020)](https://doi.org/10.1177/0093650220961965)
### Acknowledgements
Thank you to the Cerebras team, particularly, Ryan, Ryann, and Neeraj, for their support and feedback during the development of this cookbook.
*Klaus's page: Formal tone, German, white accent color, introverted personality*
### Why This Matters
Research shows that hyper-personalization significantly increases user engagement. According to Zarouali et al. (2020), personalized content that adapts to individual preferences including tone, and messaging leads to **higher perceived relevance and stronger behavioral intentions** compared to generic content.
With Cerebras' ultra-fast inference, this level of personalization becomes practical for real-time web experiences. What used to require batch processing or slow generation can now happen at page-load speed, creating truly dynamic user experiences.
## Performance
| Metric | Value |
| -------------------------- | ---------------------------------------------------------- |
| Average generation time | \~0.4s per page |
| Tokens per page | \~800-900 |
| Languages supported | English, Spanish, German (extensible) |
| Personalization dimensions | 6 (language, tone, personality, color, gender, background) |
Cerebras enables real-time personalization at scale—generate thousands of unique pages per minute.
```python theme={null}
print("\n" + "="*60)
print("⚡ CEREBRAS PERFORMANCE SUMMARY")
print("="*60)
times, tokens = [], 0
for i, user in enumerate(users):
content, elapsed, usage = generate_page_content(user)
times.append(elapsed)
tokens += usage['total_tokens']
lang = LANGUAGE_MAP.get(user.preferred_language, "en")[:2]
print(f"User {i+1}: {lang} | {user.tone} | {user.personality} → {elapsed:.2f}s")
print(f"\n📊 Average: {sum(times)/len(times):.2f}s per page")
print(f"📊 Total: {sum(times):.2f}s for {len(users)} pages")
print(f"📊 Tokens: {tokens} total ({tokens//len(users)} avg)")
print(f"\n🚀 Real-time personalization at scale!")
```
## Summary
### What We Built
A **hyper-personalized web page system** where pages adapt to each visitor:
* **Preferred colors** - Visual styling matches user preferences
* **Tone & personality** - Content adapts from formal to casual
* **Products** - Featured items match user demographics
* **Language** - Full multilingual support
All powered by **Cerebras' ultra-fast inference** (\~0.4s per page), making real-time personalization practical at scale.
### Key Patterns
1. **Schema-constrained generation**: Use `response_format` with JSON schema for reliable outputs
2. **Pydantic validation**: Validate all LLM responses before use
3. **Template separation**: LLM generates text, templates handle layout/styling
4. **Concise prompts**: Shorter prompts reduce latency and cost
### Next Steps
* Add A/B testing for different content variations
* Implement click tracking and conversion analytics
* Add more personalization dimensions (purchase history, browsing behavior)
* Deploy as a real-time API for e-commerce personalization
### Resources
* [Cerebras Inference Docs](https://inference-docs.cerebras.ai)
* [Pydantic Docs](https://docs.pydantic.dev)
* [Jinja2 Docs](https://jinja.palletsprojects.com)
* [Zarouali, B., Dobber, T., De Pauw, G., & de Vreese, C. (2020)](https://doi.org/10.1177/0093650220961965)
### Acknowledgements
Thank you to the Cerebras team, particularly, Ryan, Ryann, and Neeraj, for their support and feedback during the development of this cookbook.