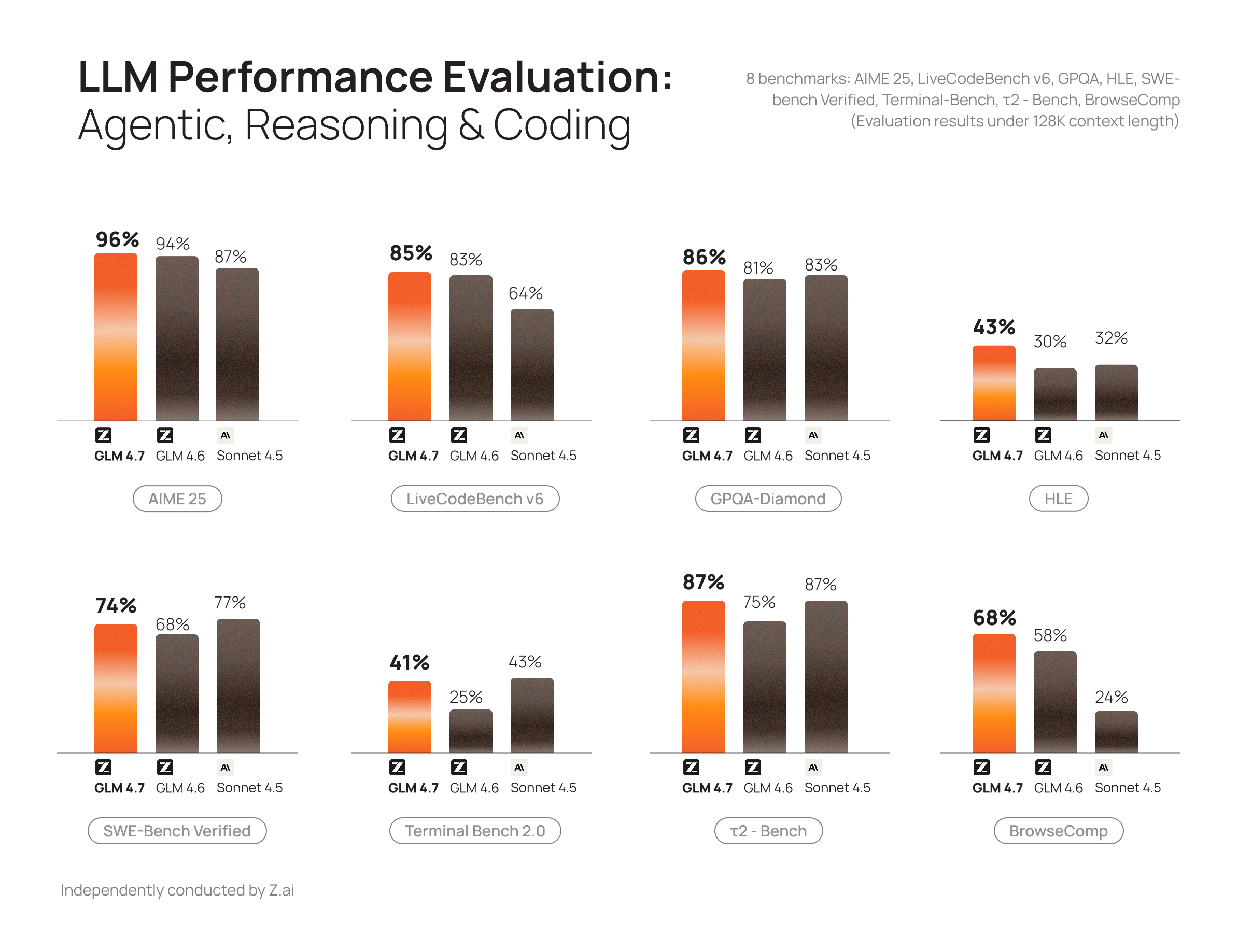
GLM 4.7 is a foundation model from Zhipu AI (Z.ai) built for coding and agentic workflows. It offers strong code generation, reasoning, and tool-use capabilities, along with new thinking controls (interleaved, preserved, and turn-level) that improve stability in multi-turn tasks.
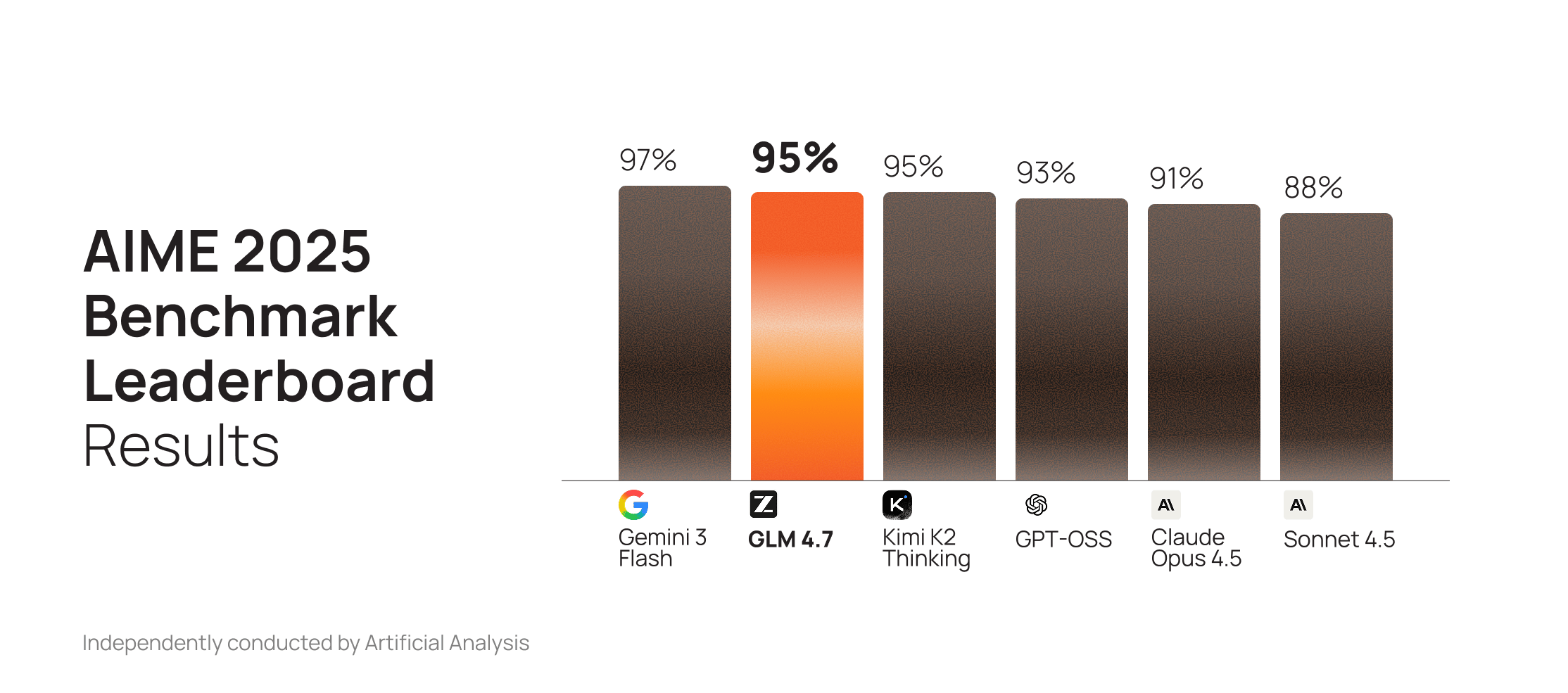 Source: [Artificial Analysis Intelligence Index](https://artificialanalysis.ai/#artificial-analysis-intelligence-index) (as of 12/30/25)
On LiveCodeBench, GLM 4.7 outperforms Anthropic and OpenAI models, trailing only Gemini 3.
Source: [Artificial Analysis Intelligence Index](https://artificialanalysis.ai/#artificial-analysis-intelligence-index) (as of 12/30/25)
On LiveCodeBench, GLM 4.7 outperforms Anthropic and OpenAI models, trailing only Gemini 3.
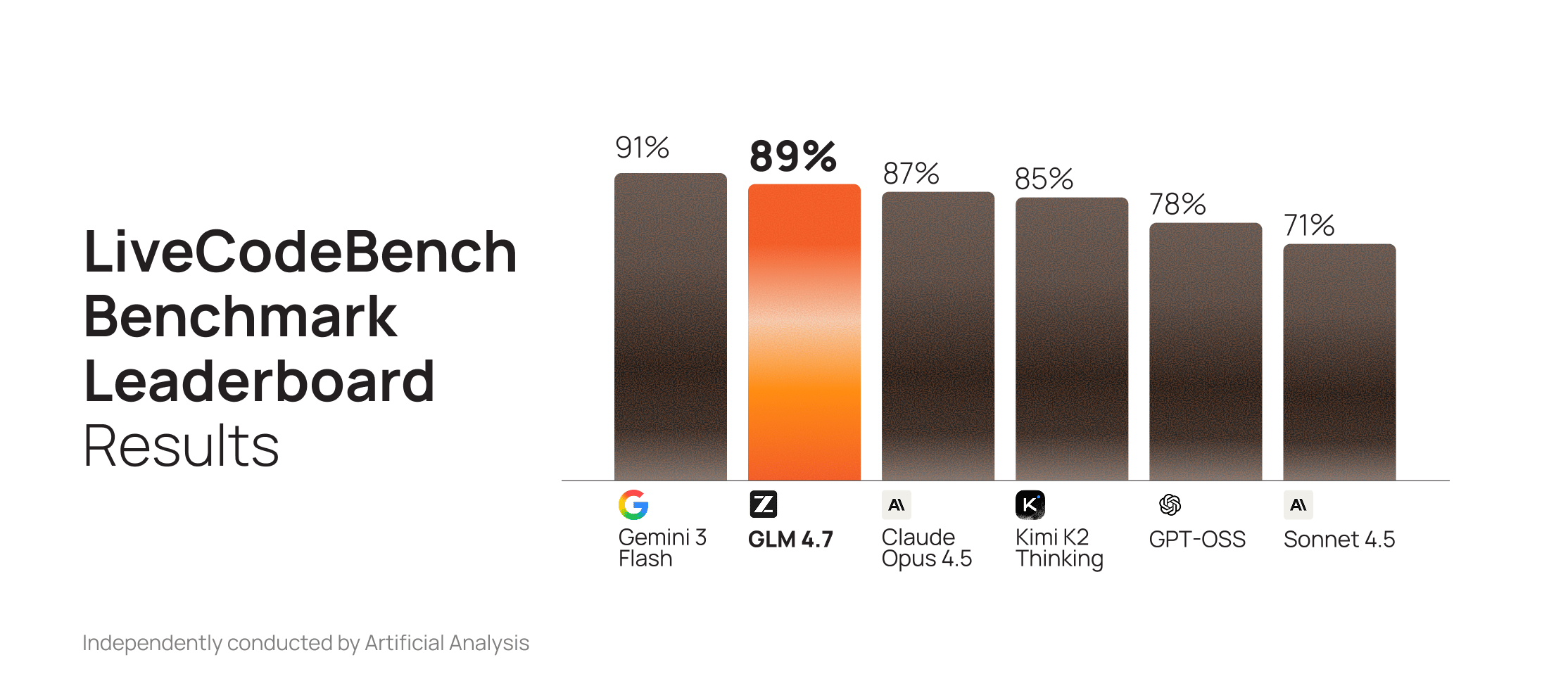 Source: [Artificial Analysis Intelligence Index](https://artificialanalysis.ai/#artificial-analysis-intelligence-index) (as of 12/30/25)
The model also improves significantly in chat, creative writing, and role-play.
Source: [Z.ai — GLM 4.7](https://z.ai/blog/glm-4.7)
# Migration Checklist
**Model and parameters**
* Set `model` to `zai-glm-4.7`
* Keep defaults unless you have a reason: `temperature=1`, `top_p=0.95`
* For deterministic outputs, adjust **either** `temperature` **or** `top_p`, not both
**Reasoning**
* Reasoning is enabled by default
* To disable: `reasoning_effort="none"` (`disable_reasoning` is deprecated as of March 24, 2026)
* To preserve traces (recommended for agentic/coding workflows): `clear_thinking: false`
**Limits**
* `max_completion_tokens`: up to 40k
* Context window: \~131k tokens
**Validation**
* Test against real workloads for randomness, latency, tool-call parsing, and long-context behavior
## API Examples
Source: [Artificial Analysis Intelligence Index](https://artificialanalysis.ai/#artificial-analysis-intelligence-index) (as of 12/30/25)
The model also improves significantly in chat, creative writing, and role-play.
Source: [Z.ai — GLM 4.7](https://z.ai/blog/glm-4.7)
# Migration Checklist
**Model and parameters**
* Set `model` to `zai-glm-4.7`
* Keep defaults unless you have a reason: `temperature=1`, `top_p=0.95`
* For deterministic outputs, adjust **either** `temperature` **or** `top_p`, not both
**Reasoning**
* Reasoning is enabled by default
* To disable: `reasoning_effort="none"` (`disable_reasoning` is deprecated as of March 24, 2026)
* To preserve traces (recommended for agentic/coding workflows): `clear_thinking: false`
**Limits**
* `max_completion_tokens`: up to 40k
* Context window: \~131k tokens
**Validation**
* Test against real workloads for randomness, latency, tool-call parsing, and long-context behavior
## API Examples