Seb Duerr
January 23, 2026
Open in GithubJanuary 23, 2026
- Preferred colors - Pages render in the user’s chosen color scheme
- Tone - Content adjusts to formal, casual, or friendly language
- Products - Featured items match user interests and demographics
- Language - Full multilingual support (English, Spanish, German)
What You’ll Learn
- Pydantic Structured Outputs - Constraining LLM responses to valid JSON schemas
- Cerebras Integration - Ultra-fast inference for real-time page personalization
- Template Separation - LLM generates content, templates handle layout/styling
- Multi-dimensional Personalization - Language, tone, personality, colors, products
Setup
Install Dependencies
Clone the Repository
This cookbook requires assets (images, templates, user data). Clone the full repository to run the notebook:hyper_personalization_assets/ directory contains:
data/users.csv- Sample user profiles with personalization preferencestemplates/email_template.html- Jinja2 HTML template for renderingimages/- Product images in different color variantsconstants.py- Configuration constants (colors, languages, guidance)
Load API Keys
Get your Cerebras API key at https://cloud.cerebras.ai (free tier available).Part 1: Pydantic Schemas
Pydantic schemas ensure the LLM returns structured, validated JSON. This is crucial for reliable template rendering.Why Pydantic Schemas Matter
| Benefit | Description |
|---|---|
| Type Safety | Validates LLM output matches expected structure |
| Auto-documentation | Field descriptions guide the LLM |
| Error Handling | Catches malformed responses before rendering |
| IDE Support | Autocomplete and type hints in your code |
Part 2: Configuration Constants
The constants are imported fromhyper_personalization_assets/constants.py. Here’s what they define:
Part 3: Content Generation Function
This function calls the Cerebras API with a structured output schema. The LLM is constrained to return valid JSON matching ourPageContent schema.
Key Implementation Details
- Schema-constrained generation: The
response_formatparameter forces the LLM to return valid JSON - Pydantic validation:
PageContent(**content_dict)validates the response - Performance tracking: We measure generation time and token usage
- Concise prompts: Shorter prompts = faster inference
Part 4: Template Rendering
Jinja2 combines LLM-generated content with user-specific styling (colors, images) into the final HTML page.Part 5: Load User Data
User profiles are loaded from CSV. Each user has unique preferences that drive personalization.Part 6: Generate & Display
This helper orchestrates the full pipeline: generate content → render template → display inline.Part 7: Generate Personalized Pages
Let’s generate pages for users with different language, tone, and personality combinations.Example Results
Here are three personalized pages generated for different users: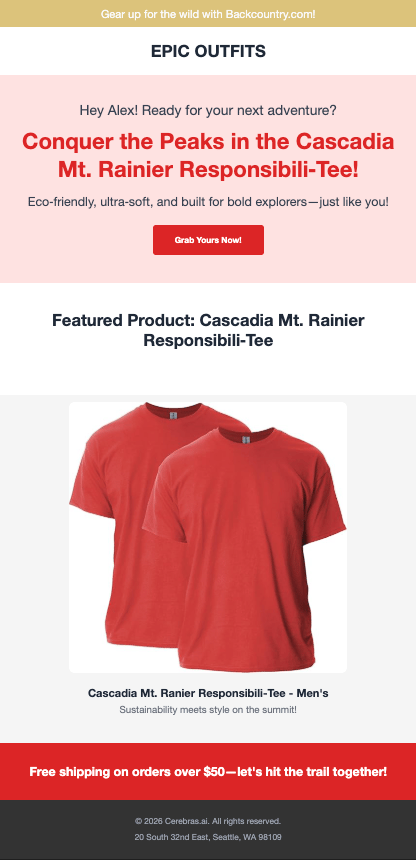
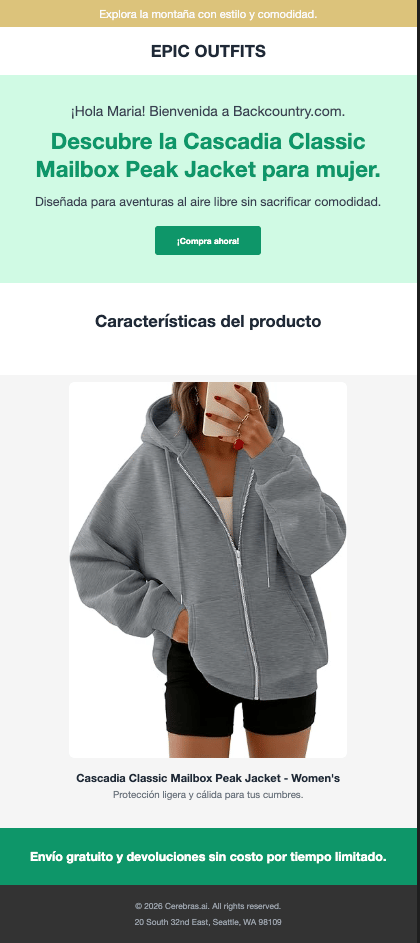
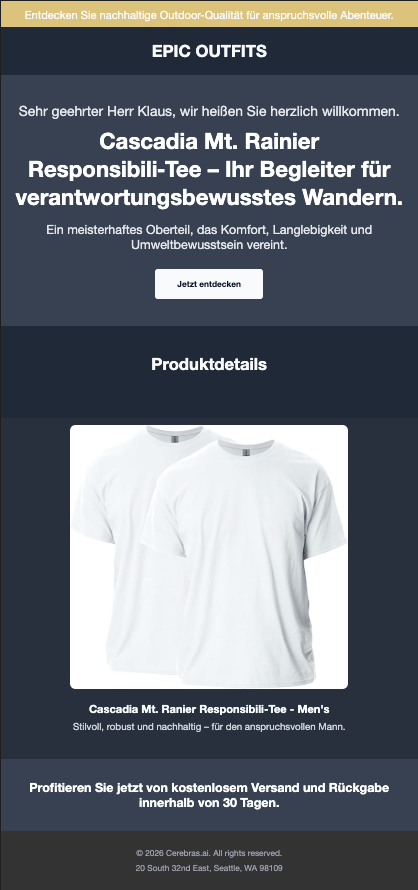
Why This Matters
Research shows that hyper-personalization significantly increases user engagement. According to Zarouali et al. (2020), personalized content that adapts to individual preferences including tone, and messaging leads to higher perceived relevance and stronger behavioral intentions compared to generic content. With Cerebras’ ultra-fast inference, this level of personalization becomes practical for real-time web experiences. What used to require batch processing or slow generation can now happen at page-load speed, creating truly dynamic user experiences.Performance
| Metric | Value |
|---|---|
| Average generation time | ~0.4s per page |
| Tokens per page | ~800-900 |
| Languages supported | English, Spanish, German (extensible) |
| Personalization dimensions | 6 (language, tone, personality, color, gender, background) |
Summary
What We Built
A hyper-personalized web page system where pages adapt to each visitor:- Preferred colors - Visual styling matches user preferences
- Tone & personality - Content adapts from formal to casual
- Products - Featured items match user demographics
- Language - Full multilingual support
Key Patterns
- Schema-constrained generation: Use
response_formatwith JSON schema for reliable outputs - Pydantic validation: Validate all LLM responses before use
- Template separation: LLM generates text, templates handle layout/styling
- Concise prompts: Shorter prompts reduce latency and cost
Next Steps
- Add A/B testing for different content variations
- Implement click tracking and conversion analytics
- Add more personalization dimensions (purchase history, browsing behavior)
- Deploy as a real-time API for e-commerce personalization
Resources
- Cerebras Inference Docs
- Pydantic Docs
- Jinja2 Docs
- Zarouali, B., Dobber, T., De Pauw, G., & de Vreese, C. (2020)