How CePO Works
CePO demonstrates how additional test-time computation can improve Llama’s reasoning.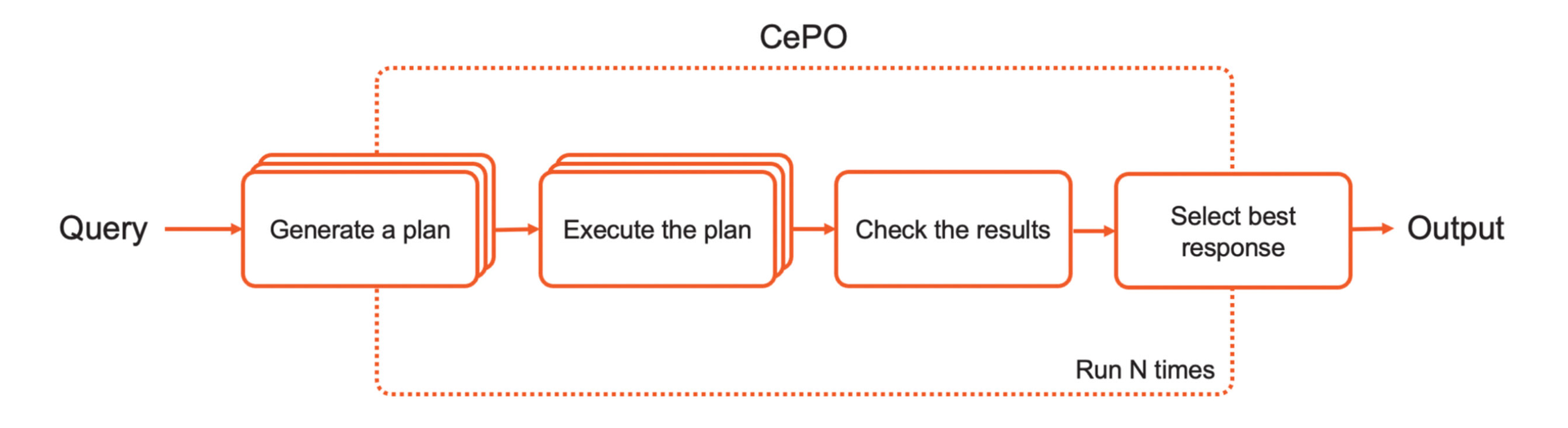
- Planning: The LLM produces a plan to solve a given problem step by step.
- Execution: The LLM executes the plan multiple times, generating multiple responses.
- Analysis: The model analyzes the responses to detect inconsistencies across executions, helping catch and correct mistakes.
- Best-of-N: Responses are evaluated within a Best-of-N framework that includes a structured confidence scoring mechanism.
Get Started with CePO
1
Step 1: Prerequisites
CePO is built on the popular, open-source OptiLLM library. To get started, install OptiLLM and make sure you have the latest version of the Cerebras Inference SDK installed.Next, configure your API key, which can be found in our developer platform.
2
Step 2: Run OptiLLM with CePO
Finally, run the OptiLLM script with CePOIf you would like to print intermediate states in the OptiLLM log, you can optionally add:
Continued Research
Further work on CePO includes:- More advanced prompting frameworks that leverage comparative reasoning.
- Synthetic data optimized for inference-time computation.
- Enhanced verification mechanisms for complex reasoning chains.
#research channel in our discord community.