What is Braintrust?
Braintrust is the AI observability platform helping teams measure, evaluate, and improve AI in production. Learn more at https://www.braintrust.dev/Prerequisites
Before you begin, ensure you have:- Cerebras API Key - Get a free API key here.
- Braintrust API Key - Visit Braintrust and create an account or log in.
- Go to Settings > AI Providers and add your Cerebras API key. Then generate a Braintrust API key.
- Python 3.7 or higher
Configure Braintrust
1
Install required dependencies
Run the following:
2
Configure environment variables
Create a
.env file in your project directory:3
Initialize the client
Set up the Cerebras client with Braintrust wrapping:
4
Start logging
Initialize a logger to automatically track all your model calls:All calls are automatically logged to Braintrust with metrics like latency, token usage, and time to first token.
5
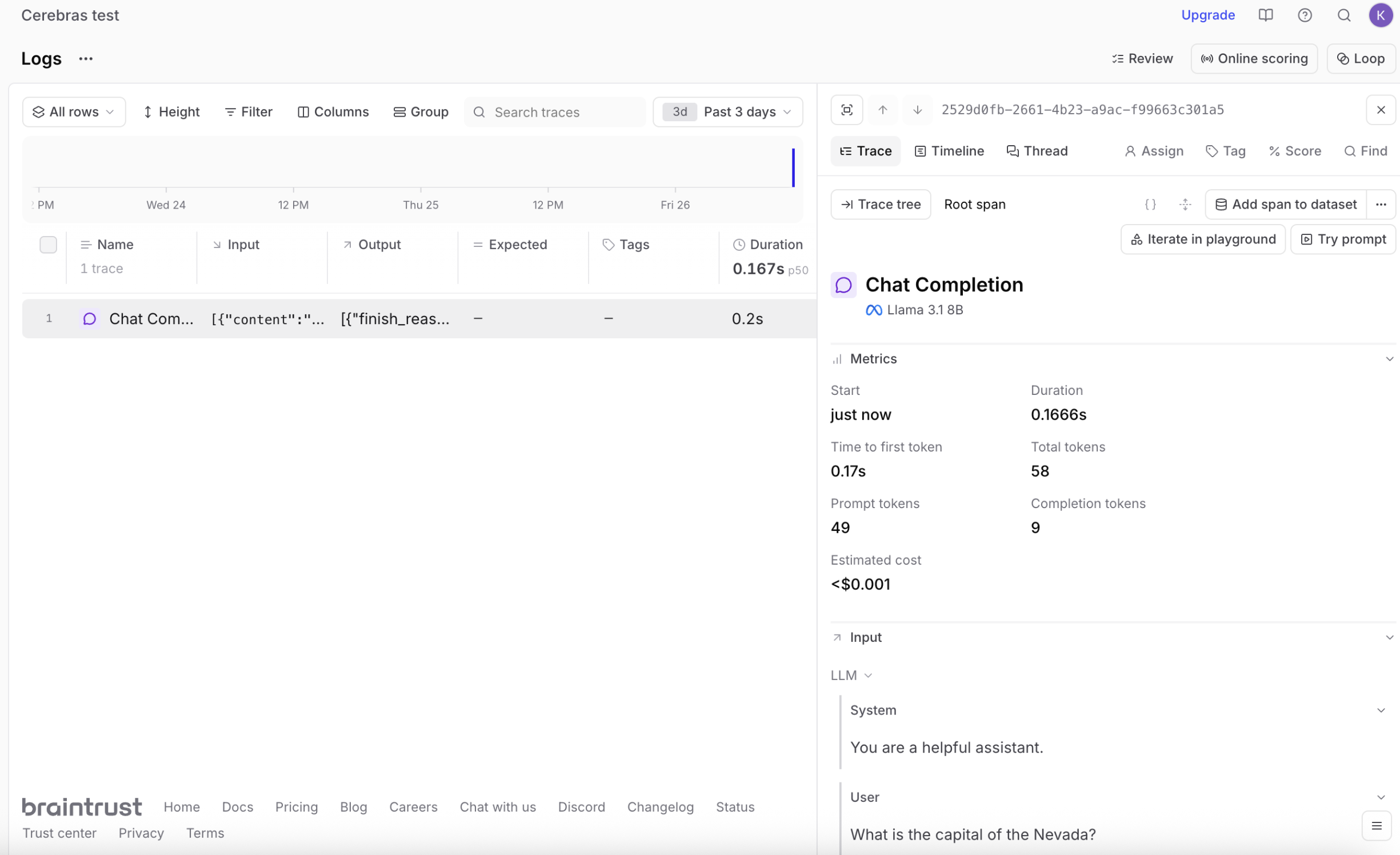
View your logs
- Open the Braintrust dashboard
- Navigate to your project
- View detailed logs with metrics
-
Reproduce and tweak prompts directly in the UI
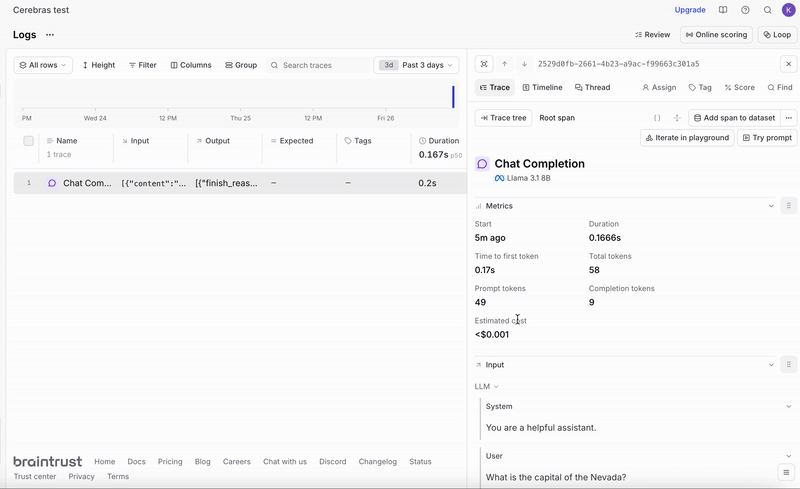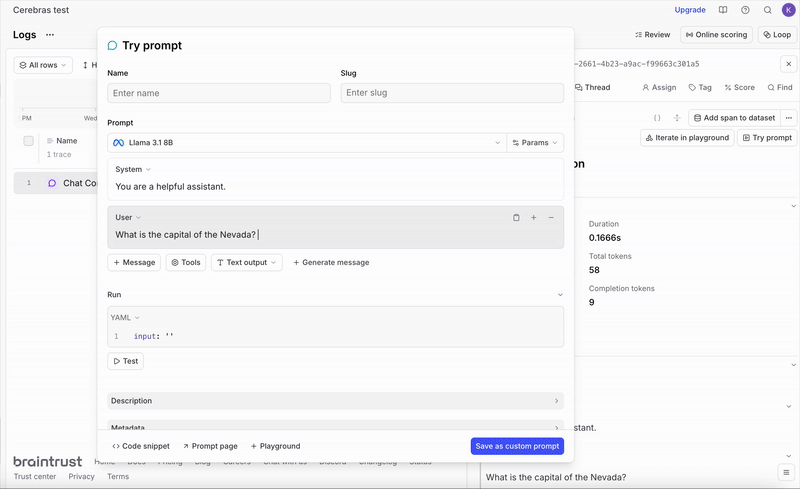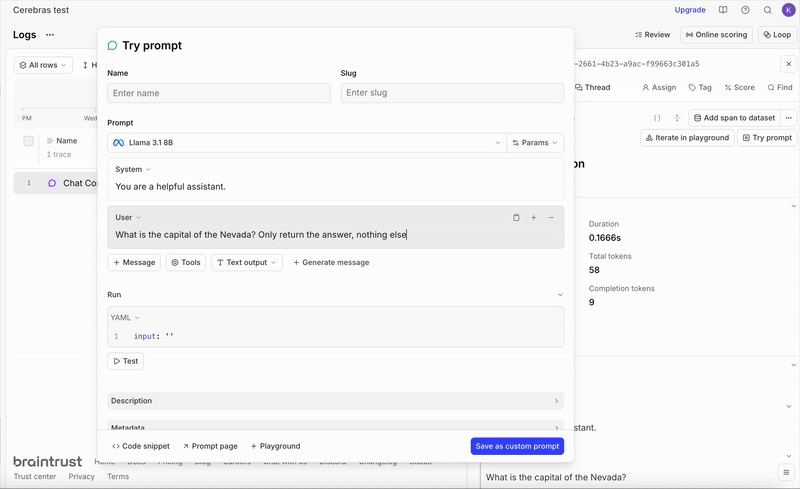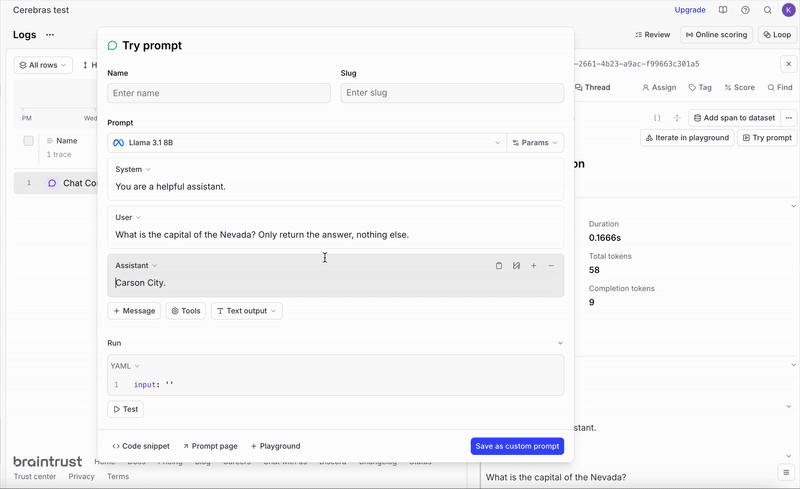
6
Run evaluations
Create evaluations to test your model’s performance:You can check these evaluations in the Braintrust dashboard: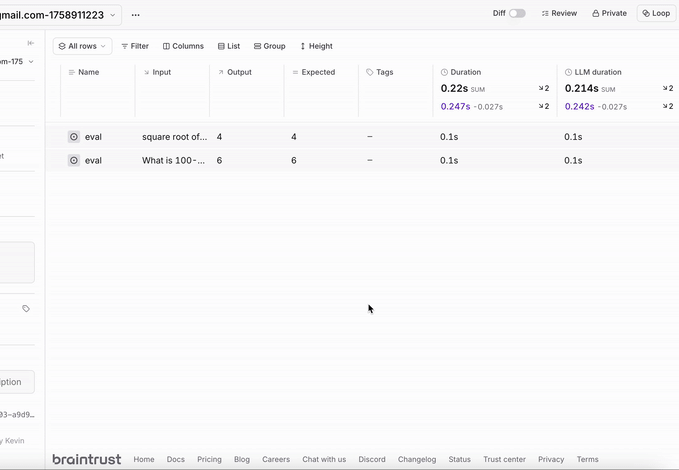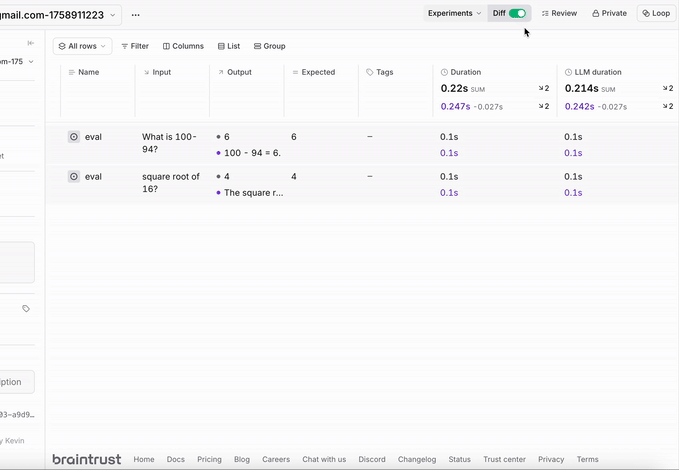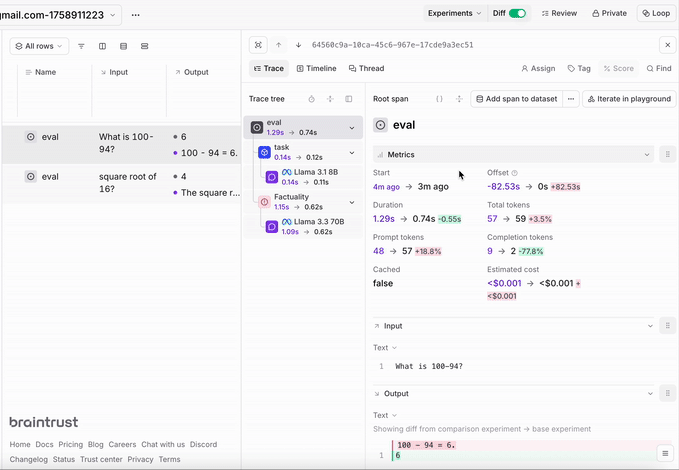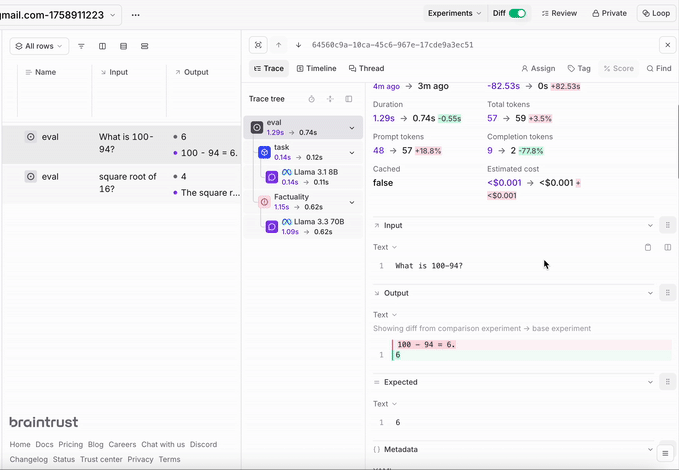
Available Models
Cerebras offers several high-performance models for your Braintrust evaluations:
Simply change the
model parameter in your API calls to switch between models.
Next Steps
- Explore the Braintrust documentation
- Migrate to GLM4.7: Ready to upgrade? Follow our migration guide to start using our latest model
- Try out different Cerebras models
- Set up custom evaluation metrics
- Build production monitoring dashboards
Troubleshooting
API Key Issues
- Verify your keys are correctly set in environment variables
- Check that Cerebras key is added to Braintrust’s AI providers
Import Errors
- Ensure all packages are installed: pip install autoevals braintrust openai
- Use a virtual environment to avoid conflicts
Connection Issues
- Verify the base URL: https://api.cerebras.ai/v1
- Check your network connection and firewall settings